The journey to Data 3.0


by Michael Li, VP of Data at Coinbase
Data is a gold mine for a company. If managed well, it provides the clarity and insights that lead to better decision-making at scale, in addition to an important tool to hold everyone accountable.
However, most companies are stuck in Data 1.0, which means they are leveraging data as a manual and reactive service. Some have started moving to Data 2.0, which employs simple automation to improve team productivity. The complexity of crypto data has opened up new opportunities in data, namely to move to the new frontier of Data 3.0, where you can scale value creation through systematic intelligence and automation. This is our journey to Data 3.0.
Coinbase is neither a finance company nor a tech company — it’s a crypto company. This distinction has big implications for how we work with data. As a crypto company, we work with three major types of data (instead of the usual one or two types of data), each of which is complex and varied:
- Blockchain: decentralized and publicly available.
- Product: large and real-time.
- Financial: high-precision and subject to many financial/legal/compliance regulations.
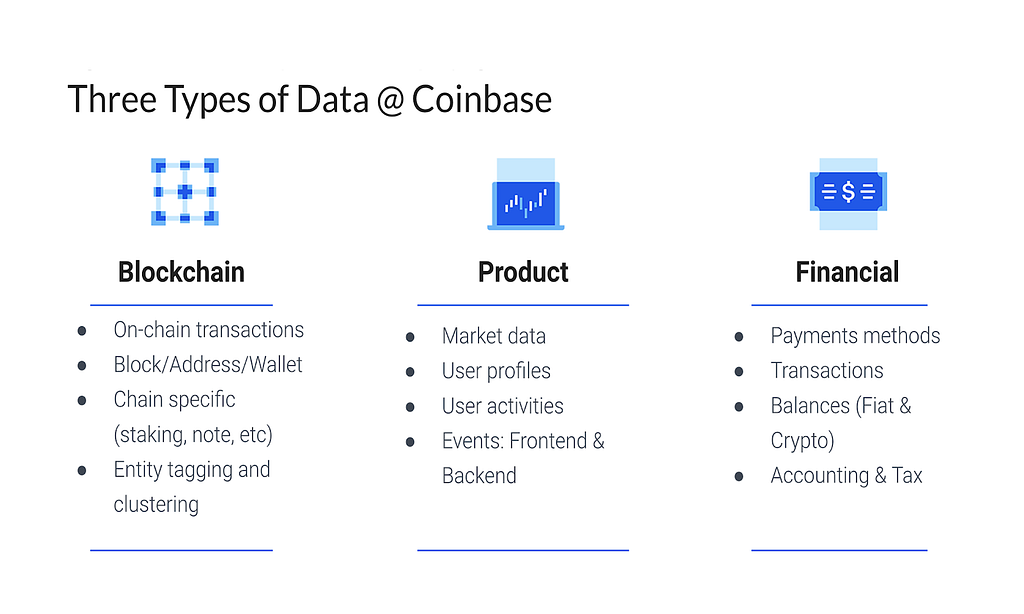
Our focus has been on how we can scale value creation by making this varied data work together, eliminating data silos, solving issues before they start and creating opportunities for Coinbase that wouldn’t exist otherwise.
Having worked at tech companies like LinkedIn and eBay, and also those in the finance sector, including Capital One, I’ve observed firsthand the evolution from Data 1.0 to Data 3.0. In Data 1.0, data is seen as a reactive function providing ad-hoc manual services or firefighting in urgent situations.
In Data 2.0, simple tooling and third-party solutions are leveraged to automate parts of the manual and repetitive tasks to improve team productivity. Although, for the most part, the data team still relies on adding more human resources to bring more value. And then, finally, in the Data 3.0 stage, data systems are created with open-source and in-house technologies in a concerted way to fundamentally scale value creation.
On the path to Data 3.0 nirvana
The biggest benefit of Data 3.0 is the efficiency and consistency created across all data flows. It empowers a company to build a comprehensive data foundation that is set up for the company’s long-term success while sustaining the immediate needs under limited resources. It may not be obvious when the company is small and quickly changing, but as the company scales and experiences hypergrowth, consistency across data flows (or lack thereof) can become a large pain point and difficult to course-correct without establishing the vision early on.
Even the best technology companies in the world can create bad habits with disparate engineering teams building bespoke data products and services to solve specific pain points. This can leave large gaps in the standardized workflows of an end-to-end data system, making it difficult to build and operate data at scale. Even worse, these one-off efforts can grow large enough to become stand-alone systems that will take time to consolidate and migrate. These often remain as legacy systems that create immense technical debt for the company over time.
Given the constant evolution of blockchain technologies and data use cases, our Data 3.0 work is far from done. That said, I am quite proud of the progress we’ve made. Here is an overview of our work and systems to date.
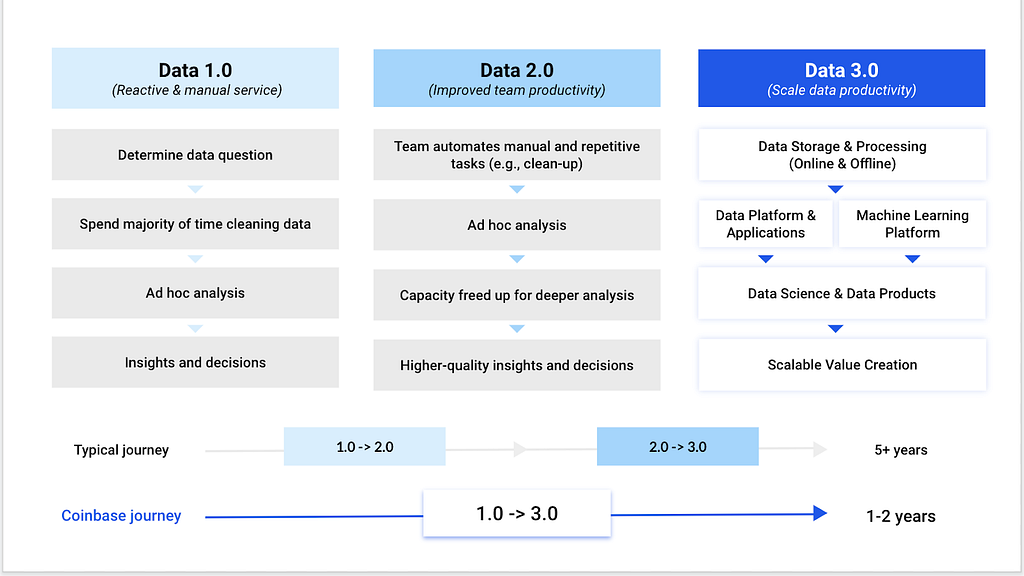
Data storage and processing
Regardless of the choices for employing specific technologies, you need a clear strategy for three major components: separation of storage, separation of compute and semantics for the “single source of truth.” Decoupling these components and setting a clear technical strategy allows us to avoid bottlenecks in performance and capacity as the company grows.
Data platform and applications
While we use a combination of in-house technologies, open-source tools and vendor solutions to meet the various demands, we make explicit trade-offs in deciding specific solutions for each category so we don’t create duplication or ambiguity down the road. This applies to how we manage our eventing system, data orchestration workflow, business intelligence layer and experimentation platform. It also results in highly decoupled and scalable architecture.
Machine learning and platform
While this is probably the most “shiny” part of the data team given the hype of AI in recent years, it is also the most cross-functional component of the data team. Our truly end-to-end machine learning platform, Nostradamus, empowers all machine learning models at Coinbase, including data pipelines, training, deployment, serving and experimentation. Because the machine learning platform was built with all other parts of the data ecosystem in mind, not only is it designed to enable machine learning to solve immediate problems, but also to grow and scale with the business.
Data science and data products
These two areas are probably the most end-user-friendly part of the data team because they are basically the presentation layer of distilled data insights that are curated to delight and create value for our customers. They are also the most direct beneficiaries from all the efforts above.
The most prominent team mandate is that data scientists should be taking themselves out of the machinery and focusing on enabling the machinery to serve data and generate value for consumers in a scalable way (instead of being a middleman between machinery and data consumers).
This piece originally appeared in TechCrunch.
The journey to Data 3.0 was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
